for Technical interviews:
http://no1tutorial.com/
learn step by step technologies:
http://no1tutorial.com/
Data Driven Automation Framework:-
Data Driven Scripts
These data driven scripts often still contain the hard coded and sometimes very fragile recognition strings for the window components they navigate. When this is the case, the scripts are easily broken when an application change or revision occurs. And when these scripts start breaking, we are not necessarily talking about just a few. We are sometimes talking about a great many, if not all the scripts, for the entire application.
Reusable Code, Error Correction and Synchronization:
Application-independent component functions are developed that accept application-specific variable data. Once these component functions exist, they can be used on each and every application we choose to test with the framework.
The keyword driven automation framework is initially the hardest and most time-consuming data driven approach to implement. After all, we are trying to fully insulate our tests from both the many failings of the automation tools, as well as changes to the application itself.
Keyword Driven Automation Framework Model
Project Guidelines
In brief, the framework itself is really defined by the Core Data Driven Engine, the Component Functions, and the Support Libraries. While the Support Libraries provide generic routines useful even outside the context of a keyword driven framework, the core engine and Component Functions are highly dependent on the existence of all three elements.
The Application Map is one of the most critical items in our framework. It is how we map our objects from names we humans can recognize to a data format useful for the automation tool. The testers for a given project will define a naming convention or specific names for each component in each window as well as a name for the window itself. We then use the Application Map to associate that name to the identification method needed by the automation tool to locate and properly manipulate the correct object in the window.
 Component Functions:
Component Functions:
Component Functions are those functions that actively manipulate or interrogate component objects. In our automation framework we will have a different Component Function module for each Type of component we encounter (Window, CheckBox, TextBox, Image, Link, etc..).
 Test Tables:
Test Tables:
This discussion on the Core Data Driven Engine has identified three separate modules (StepDriver, SuiteDriver, and CycleDriver) that comprise the Core. This does not, however, make this three-module design an automation framework requirement. It may be just as valid to sum up all the functionality of those three modules into one module, or any number of discreet modules more suitable to the framework design developed.
Thanks,

In addition to this table-processing role, each of the Driver modules has its own set of System-Level keywords or commands also called Driver Commands. These commands instruct the module to do something other than normal table processing.
1.3.7 The Core Data Driven Engine:

Low-level Test Tables or Step Tables contain the detailed step-by-step instructions of our tests. Using the object names found in the Application Map, and the vocabulary defined by the Component Functions; these tables specify what document, what component, and what action to take on the component. The following three tables are examples of Step Tables comprised of instructions to be processed by the StepDriver module. The StepDriver module is the one that initially parses and routes all low-level instructions that ultimately drive our application.
Each of these Component Function modules will define the keywords or "action words" that are valid for the particular component type it handles. For example, the Textbox Component Function module would define and implement the actions or keywords that are valid on a Textbox. These keywords would describe actions like those in Table 6:
Code and Documentation Standards
Table 2 reiterates the actual data table record run by the automation framework above:
The data table records contain the keywords that describe the actions we want to perform. They also provide any additional data needed as input to the application, and where appropriate, the benchmark information we use to verify the state of our components and the application in general.
A test automation framework relying on data driven scripts is definitely the easiest and quickest to implement if you have and keep the technical staff to maintain it. But it is the hardest of the data driven approaches to maintain and perpetuate and very often leads to long-term failure
Another common feature of data driven scripts is that virtually all of the test design effort for the application is developed in the scripting language of the automation tool. Either that, or it is duplicated in both manual and automated script versions. This means that everyone involved with automated test development or automated test execution for the application must likely become proficient in the environment and programming language of the automation tool.
for Technical interviews:
http://no1tutorial.com/
learn step by step technologies:
http://no1tutorial.com/
http://no1tutorial.com/
learn step by step technologies:
http://no1tutorial.com/
Data Driven Automation Framework:-
Data Driven Scripts
Data driven scripts are those application-specific scripts captured or manually coded in the automation tool’s proprietary language and then modified to accommodate variable data. Variables will be used for key application input fields and program selections allowing the script to drive the application with external data supplied by the calling routine or the shell that invoked the test script.
These data driven scripts often still contain the hard coded and sometimes very fragile recognition strings for the window components they navigate. When this is the case, the scripts are easily broken when an application change or revision occurs. And when these scripts start breaking, we are not necessarily talking about just a few. We are sometimes talking about a great many, if not all the scripts, for the entire application.
Variable Data, Hard Coded Component Identification:
Figure 1 is an example of activating a server-side image map link in a web application with an automation tool scripting language:
Image Click "DocumentTitle=Welcome;\;ImageIndex=1" "Coords=25,20"
|
This particular scenario of clicking on the image map might exist thousands of times throughout all the scripts that test this application. The preceding example identifies the image by the title given to the document and the index of the image on the page. The hard coded image identification might work successfully all the way through the production release of that version of the application. Consequently, testers responsible for the automated test scripts may gain a false sense of security and satisfaction with these results.
However, the next release cycle may find some or all of these scripts broken because either the title of the document or the index of the image has changed. Sometimes, with the right tools, this might not be too hard to fix. Sometimes, no matter what tools, it will be frustratingly difficult.
Remember, we are potentially talking about thousands of broken lines of test script code. And this is just one particular change. Where there is one, there will likely be others.
Highly Technical or Duplicate Test Designs:
Findings:
Keyword or Table Driven Test Automation
Nearly everything discussed so far defining our ideal automation framework has been describing the best features of "keyword driven" test automation. Sometimes this is also called "table driven" test automation. It is typically an application-independent automation framework designed to process our tests. These tests are developed as data tables using a keyword vocabulary that is independent of the test automation tool used to execute them. This keyword vocabulary should also be suitable for manual testing, as you will soon see.
Action, Input Data, and Expected Result ALL in One Record:
For example, to verify the value of a user ID textbox on a login page, we might have a data table record as seen in Table 1:
WINDOW
|
COMPONENT
|
ACTION
|
EXPECTED
VALUE
|
LoginPage
|
UserIDTextbox
|
VerifyValue
|
"MyUserID"
|
Figure 2 presents pseudo-code that would interpret the data table record from Table 1 and Table 2. In our design, the primary loop reads a record from the data table, performs some high-level validation on it, sets focus on the proper object for the instruction, and then routes the complete record to the appropriate component function for full processing. The component function is responsible for determining what action is being requested, and to further route the record based on the action.
Framework Pseudo-Code
|
| Primary Record Processor Module: Verify "LoginPage" Exists. (Attempt recovery if not) Set focus to "LoginPage". Verify "UserIDTextbox" Exists. (Attempt recovery if not) Find "Type" of component "UserIDTextbox". (It is a Textbox) Call the module that processes ALL Textbox components. Textbox Component Module: Validate the action keyword "VerifyValue". Call the Textbox.VerifyValue function. Textbox.VerifyValue Function: Get the text stored in the "UserIDTextbox" Textbox. Compare the retrieved text to "MyUserID". Record our success or failure. |
Application-independent component functions are developed that accept application-specific variable data. Once these component functions exist, they can be used on each and every application we choose to test with the framework.
Test Design for Man and Machine, With or Without the Application:
Note how the record uses a vocabulary that can be processed by both man and machine. With minimal training, a human tester can be made to understand the record instruction as deciphered in Figure 3:
Once they learn or can reference this simple vocabulary, testers can start designing tests without knowing anything about the automation tool used to execute them.
Another advantage of the keyword driven approach is that testers can develop tests without a functioning application as long as preliminary requirements or designs can be determined. All the tester needs is a fairly reliable definition of what the interface and functional flow is expected to be like. From this they can write most, if not all, of the data table test records.
Sometimes it is hard to convince people that this advantage is realizable. Yet, take our login example from Table 2 and Figure 3. We do not need the application to construct any login tests. All we have to know is that we will have a login form of some kind that will accept a user ID, a password, and contain a button or two to submit or cancel the request. A quick discussion with development can confirm or modify our determinations. We can then complete the test table and move on to another.
We can develop other tests similarly for any part of the product we can receive or deduce reliable information. In fact, if in such a position, testers can actually help guide the development of the UI and flow, providing developers with upfront input on how users might expect the product to function. And since the test vocabulary we use is suitable for both manual and automated execution, designed testing can commence immediately once the application becomes available.
It is, perhaps, important to note that this does not suggest that these tests can be executed automatically as soon as the application becomes available. The test record in Table 2 may be perfectly understood and executable by a person, but the automation framework knows nothing about the objects in this record until we can provide that additional information. That is a separate piece of the framework we will learn about when we discuss application mapping.
The keyword driven automation framework is initially the hardest and most time-consuming data driven approach to implement. After all, we are trying to fully insulate our tests from both the many failings of the automation tools, as well as changes to the application itself.
Findings:
To accomplish this, we are essentially writing enhancements to many of the component functions already provided by the automation tool: such as error correction, prevention, and enhanced synchronization.
Fortunately, this heavy, initial investment is mostly a one-shot deal. Once in place, keyword driven automation is arguably the easiest of the data driven frameworks to maintain and perpetuate providing the greatest potential for long-term success.
Additionally, there may now be commercial products suitable for your needs to decrease, but not eliminate, much of the up-front technical burden of implementing such a framework. This was not the case just a few years ago.
Hybrid Test Automation.
The most successful automation frameworks generally accommodate both keyword driven testing as well as data driven scripts. This allows data driven scripts to take advantage of the powerful libraries and utilities that usually accompany a keyword driven architecture.
The framework utilities can make the data driven scripts more compact and less prone to failure than they otherwise would have been. The utilities can also facilitate the gradual and manageable conversion of existing scripts to keyword driven equivalents when and where that appears desirable.
On the other hand, the framework can use scripts to perform some tasks that might be too difficult to re-implement in a pure keyword driven approach, or where the keyword driven capabilities are not yet in place.
Keyword Driven Automation Framework Model
The following automation framework model is the result of over 18 months of planning, design, coding, and sometimes trial and error. That is not to say that it took 18 months to get it working--it was actually a working prototype at around 3 person-months. Specifically, one person working on it for 3 months!
The model focuses on implementing a keyword driven automation framework. It does not include any additional features like tracking requirements or providing traceability between automated test results and any other function of the test process. It merely provides a model for a keyword driven execution engine for automated tests.
The commercially available frameworks generally have many more features and much broader scope. Of course, they also have the price tag to reflect this.
The project was informally tasked to follow the guidelines or practices below:
- Implement a test strategy that will allow reasonably intuitive tests to be developed and executed both manually and via the automation framework.
- The test strategy will allow each test to include the step to perform, the input data to use, and the expected result all together in one line or record of the input source.
- Implement a framework that will integrate keyword driven testing and traditional scripts, allowing both to benefit from the implementation.
- Implement the framework to be completely application-independent since it will need to test at least 4 or 5 different applications once deployed.
- The framework will be fully documented and published.
- The framework will be publicly shared on the intranet for others to use and eventually (hopefully) co-develop.
The first thing we did was to define standards for source code files and headers that would provide for in-context documentation intended for publication. This included standards for how we would use headers and what type of information would go into them.
Each source file would start with a structured block of documentation describing the purpose of the module. Each function or subroutine would likewise have a leading documentation block describing the routine, its arguments, possible return codes, and any errors it might generate. Similar standards were developed for documenting the constants, variables, dependencies, and other features of the modules.
We then developed a tool that would extract and publish the documentation in HTML format directly from the source and header files. We did this to minimize synchronization problems between the source code and the documentation, and it has worked very well.
It is beyond the scope of this work to illustrate how this is done. In order to produce a single HTML document we parse the source file and that source file’s primary headers. We format and link public declarations from the headers to the detailed documentation in the source as well as link to any external references for other documentation. We also format and group public constants, properties or variables, and user-defined types into the appropriate sections of the HTML publication.
One nice feature about this is that the HTML publishing tool is made to identify the appropriate documentation blocks and include them pretty much "as is". This enables the inclusion of HTML tags within the source documentation blocks that will be properly interpreted by a browser. Thus, for publication purposes, we can include images or other HTML elements by embedding the proper tags.
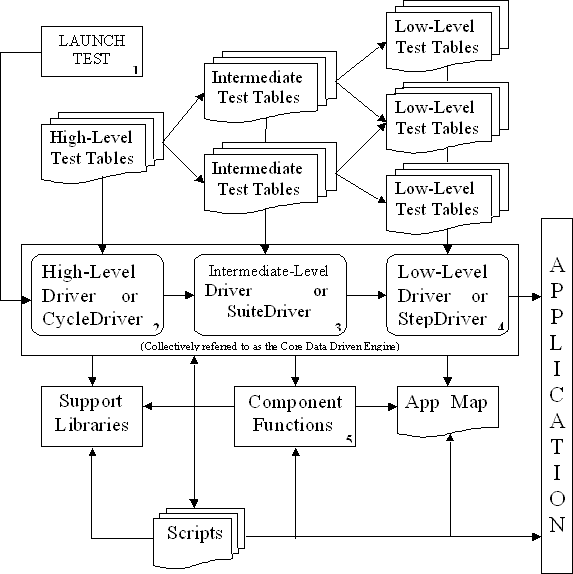
Figure 4 is a diagram representing the design of our automation framework. It is followed by a description of each of the elements within the framework and how they interact. Some readers may recognize portions of this design. It is a compilation of keyword driven automation concepts from several sources. These include Linda Hayes with WorkSoft, Ed Kit from Software Development Technolgies, Hans Buwalda from CMG Corp, myself, and a few others.
The test execution starts with the LAUNCH TEST(1) script. This script invokes the Core Data Driven Engine by providing one or more High-Level Test Tables to CycleDriver(2). CycleDriver processes these test tables invoking the SuiteDriver(3) for each Intermediate-Level Test Table it encounters. SuiteDriver processes these intermediate-level tables invoking StepDriver(4) for each Low-Level Test Table it encounters. As StepDriver processes these low-level tables it attempts to keep the application in synch with the test. When StepDriver encounters a low-level command for a specific component, it determines what Type of component is involved and invokes the corresponding Component Function(5) module to handle the task.
All of these elements rely on the information provided in the App Map to interface or bridge the automation framework with the application being tested. Each of these elements will be described in more detail in the following sections.

The Application Map is one of the most critical items in our framework. It is how we map our objects from names we humans can recognize to a data format useful for the automation tool. The testers for a given project will define a naming convention or specific names for each component in each window as well as a name for the window itself. We then use the Application Map to associate that name to the identification method needed by the automation tool to locate and properly manipulate the correct object in the window.
The Application Map:
Not only does it give us the ability to provide useful names for our objects, it also enables our scripts and keyword driven tests to have a single point of maintenance on our object identification strings. Thus, if a new version of an application changes the title of our web page or the index of an image element within it, they should not affect our test tables. The changes will require only a quick modification in one place--inside the Application Map.
Figure 5 shows a simple HTML page used in one frame of a HTML frameset. Table 3 shows the object identification methods for this page for an automation tool. This illustrates how the tool’s recorded scripts might identify multiple images in the header frame or top frame of a multi-frame web page. This top frame contains the HTML document with four images used to navigate the site. Notice that these identification methods are literal strings and potentially appear many times in traditional scripts (a maintenance nightmare!):
Simple HTML Document With Four Images
|
 |
Script referencing HTML Document Components with Literal Strings
| |
| OBJECT | IDENTIFICATION METHOD |
Window
| "WindowTag=WebBrowser" |
Frame
| "FrameID=top" |
Image
| "FrameID=top;\;DocumentTitle=topFrame" |
Image
| "FrameID=top;\;DocumentTitle=topFrame;\;ImageIndex=1" |
Image
| "FrameID=top;\;DocumentTitle=topFrame;\;ImageIndex=2" |
Image
| "FrameID=top;\;DocumentTitle=topFrame;\;ImageIndex=3" |
Image
| "FrameID=top;\;DocumentTitle=topFrame;\;ImageIndex=4" |
Table 3
This particular web page is simple enough. It contains only four images. However, when we look at Table 3, how do we determine which image is for Product information, and which is for Services? We should not assume they are in any particular order based upon how they are presented visually. Consequently, someone trying to decipher or maintain scripts containing these identification strings can easily get confused.
An Application Map will give these elements useful names, and provide our single point of maintenance for the identification strings as shown in Table 4. The Application Map can be implemented in text files, spreadsheet tables, or your favorite database table format. The Support Libraries just have to be able to extract and cache the information for when it is needed.
An Application Map Provides Named References for Components
| |
| REFERENCE | IDENTIFICATION METHOD |
Browser
| "WindowTag=WebBrowser" |
TopFrame
| "FrameID=top" |
TopPage
| "FrameID=top;\;DocumentTitle=topFrame" |
CompInfoImage
| "FrameID=top;\;DocumentTitle=topFrame;\;ImageIndex=1" |
ProductsImage
| "FrameID=top;\;DocumentTitle=topFrame;\;ImageIndex=2" |
ServicesImage
| "FrameID=top;\;DocumentTitle=topFrame;\;ImageIndex=3" |
SiteMapImage
| "FrameID=top;\;DocumentTitle=topFrame;\;ImageIndex=4" |
With the preceding definitions in place, the same scripts can use variables with values from the Application Map instead of those string literals. Our scripts can now reference these image elements as shown in Table 5. This reduces the chance of failure caused by changes in the application and provides a single point of maintenance in the Application Map for the identification strings used throughout our tests. It can also make our scripts easier to read and understand.
Script Using Variable References Instead of Literal Strings
| |
| OBJECT | IDENTIFICATION METHOD |
Window
|
Browser
|
Frame
|
TopFrame
|
Document
|
TopPage
|
Image
|
CompInfoImage
|
Image
|
ProductsImage
|
Image
|
ServicesImage
|
Image
|
SiteMapImage
|
Component Functions:Component Functions are those functions that actively manipulate or interrogate component objects. In our automation framework we will have a different Component Function module for each Type of component we encounter (Window, CheckBox, TextBox, Image, Link, etc..).
Our Component Function modules are the application-independent extensions we apply to the functions already provided by the automation tool. However, unlike those provided by the tool, we add the extra code to help with error detection, error correction, and synchronization. We also write these modules to readily use our application-specific data stored in the Application Map and test tables as necessary. In this way, we only have to develop these Component Functions once, and they will be used again and again by every application we test.
Another benefit from Component Functions is that they provide a layer of insulation between our application and the automation tool. Without this extra layer, changes or "enhancements" in the automation tool itself can break existing scripts and our table driven tests. With these Component Functions, however, we can insert a "fix"--the code necessary to accommodate these changes that will avert breaking our tests.
Component Function Keywords Define Our Low-Level Vocabulary:
Some Component Function Keywords for a Textbox
| |
| KEYWORD | ACTION PERFORMED |
| InputText | Enter new value into the Textbox |
| VerifyValue | Verify the current value of the Textbox |
| VerifyProperty | Verify some other attribute of the Textbox |
Table 6
Each action embodied by a keyword may require more information in order to complete its function. The InputText action needs an additional argument that tells the function what text it is suppose to input. The VerifyProperty action needs two additional arguments, (1) the name of the property we want to verify, and (2) the value we expect to find. And, while we need no additional information to Click a Pushbutton, a Click action for an Image map needs to know where we want the click on the image to occur.
These Component Function keywords and their arguments define the low-level vocabulary and individual record formats we will use to develop our test tables. With this vocabulary and the Application Map object references, we can begin to build test tables that our automation framework and our human testers can understand and properly execute.
Test Tables:
Step Table: LaunchSite
| ||
COMMAND/DOCUMENT
|
PARAMETER/ACTION
|
PARAMETER
|
LaunchBrowser
|
Default.htm
| |
Browser
|
VerifyCaption
|
"Login"
|
Step Table: Login
| |||
DOCUMENT
|
COMPONENT
|
ACTION
|
PARAMETER
|
LoginPage
|
UserIDField
|
InputText
|
"MyUserID"
|
LoginPage
|
PasswordField
|
InputText
|
"MyPassword"
|
LoginPage
|
SubmitButton
|
Click
| |
Step Table: LogOffSite
| ||
DOCUMENT
|
COMPONENT
|
ACTION
|
TOCPage
|
LogOffButton
|
Click
|
Note:
In Table 7 we used a System-Level keyword, LaunchBrowser. This is also called a Driver Command. A Driver Command is a command for the framework itself and not tied to any particular document or component. Also notice that test tables often consist of records with varying numbers of fields.
In Table 7 we used a System-Level keyword, LaunchBrowser. This is also called a Driver Command. A Driver Command is a command for the framework itself and not tied to any particular document or component. Also notice that test tables often consist of records with varying numbers of fields.
Intermediate-Level Test Tables or Suite Tables do not normally contain such low-level instructions. Instead, these tables typically combine Step Tables into Suites in order to perform more useful tasks. The same Step Tables may be used in many Suites. In this way we only develop the minimum number of Step Tables necessary. We then mix-and-match them in Suites according to the purpose and design of our tests, for maximum reusability.
The Suite Tables are handled by the SuiteDriver module which passes each Step Table to the StepDriver module for processing.
For example, a Suite using two of the preceding Step Tables might look like Table 10:
Suite Table: StartSite
| |
STEP TABLE REFERENCE
|
TABLE PURPOSE
|
LaunchSite
|
Launch web app for test
|
Login
|
Login "MyUserID" to app
|
Other Suites might combine other Step Tables like these:
Suite Table: VerifyTOCPage
| |
STEP TABLE REFERENCE
|
TABLE PURPOSE
|
VerifyTOCContent
|
Verify text in Table of Contents
|
VerifyTOCLinks
|
Verify links in Table of Contents
|
Suite Table: ShutdownSite
| |
STEP TABLE REFERENCE
|
TABLE PURPOSE
|
LogOffSite
|
Logoff the application
|
ExitBrowser
|
Close the web browser
|
High-Level Test Tables or Cycle Tables combine intermediate-level Suites into Cycles. The Suites can be combined in different ways depending upon the testing Cycle we wish to execute (Regression, Acceptance, Performance…). Each Cycle will likely specify a different type or number of tests. These Cycles are handled by the CycleDriver module which passes each Suite to SuiteDriver for processing.
A simple example of a Cycle Table using the full set of tables seen thus far is shown in Table 13.
We have already talked about the primary purpose of each of the three modules that make up the Core Data Driven Engine part of the automation framework. But let us reiterate some of that here.
CycleDriver processes Cycles, which are high-level tables listing Suites of tests to execute. CycleDriver reads each record from the Cycle Table, passing SuiteDriver each Suite Table it finds during this process.
SuiteDriver processes these Suites, which are intermediate-level tables listing Step Tables to execute. SuiteDriver reads each record from the Suite Table, passing StepDriver each Step Table it finds during this process.
StepDriver processes these Step Tables, which are records of low-level instructions developed in the keyword vocabulary of our Component Functions. StepDriver parses these records and performs some initial error detection, correction, and synchronization making certain that the document and\or the component we plan to manipulate are available and active. StepDriver then routes the complete instruction record to the appropriate Component Function for final execution.
Let us again show a sample Step Table record in Table 14 and the overall framework pseudo-code that will process it in Figure 6.
Single Step Table Record
| |||
DOCUMENT
|
COMPONENT
|
ACTION
|
EXPECTED
VALUE
|
LoginPage
|
UserIDTextbox
|
VerifyValue
|
"MyUserID"
|
Framework Pseudo-Code
|
| Primary Record Processor Module: Verify "LoginPage" Exists. (Attempt recovery if not) Set focus to "LoginPage". Verify "UserIDTextbox" Exists. (Attempt recovery if not) Find "Type" of component "UserIDTextbox". (It is a Textbox) Call the module that processes ALL Textbox components. Textbox Component Module: Validate the action keyword "VerifyValue". Call the Textbox.VerifyValue function. Textbox.VerifyValue Function: Get the text stored in the "UserIDTextbox" Textbox. Compare the retrieved text to "MyUserID". Record our success or failure. |
In Figure 6 you may notice that it is not StepDriver that validates the action command or keyword VerifyValue that will be processed by the Textbox Component Function Module. This allows the Textbox module to be further developed and expanded without affecting StepDriver or any other part of the framework. While there are other schemes that might allow StepDriver to effectively make this validation dynamically at runtime, we still chose to do this in the Component Functions themselves.
System-Level Commands or Driver Commands:
For example, the previously shown LaunchSite Step Table issued the LaunchBrowser StepDriver command. This command instructs StepDriver to start a new Browser window with the given URL. Some common Driver Commands to consider:
Common Driver Commands
| |
| COMMAND | PURPOSE |
| UseApplicationMap | Set which Application Map(s) to use |
| LaunchApplication | Launch a standard application |
| LaunchBrowser | Launch a web-based app via URL |
| CallScript | Run an automated tool script |
| WaitForWindow | Wait for Window or Browser to appear |
| WaitForWindowGone | Wait for Window or Browser to disappear |
| Pause or Sleep | Pause for a specified amount of time |
| SetRecoveryProcess | Set an AUT recovery process |
| SetShutdownProcess | Set an AUT shutdown process |
| SetRestartProcess | Set an AUT restart process |
| SetRebootProcess | Set a System Reboot process |
| LogMessage | Enter a message in the log |
These are just some examples of possible Driver Commands. There are surely more that have not been listed and some here which you may not need implemented.
This discussion on the Core Data Driven Engine has identified three separate modules (StepDriver, SuiteDriver, and CycleDriver) that comprise the Core. This does not, however, make this three-module design an automation framework requirement. It may be just as valid to sum up all the functionality of those three modules into one module, or any number of discreet modules more suitable to the framework design developed.
All for One, and One for All:
1.3.8 The Support Libraries:
The Support Libraries are the general-purpose routines and utilities that let the overall automation framework do what it needs to do. They are the modules that provide things like:
The Support Libraries are the general-purpose routines and utilities that let the overall automation framework do what it needs to do. They are the modules that provide things like:
- File Handling
- String Handling
- Buffer Handling
- Variable Handling
- Database Access
- Logging Utilities
- System\Environment Handling
- Application Mapping Functions
- System Messaging or System API Enhancements and Wrappers
They also provide traditional automation tool scripts access to the features of our automation framework including the Application Map functions and the keyword driven engine itself. Both of these items can vastly improve the reliability and robustness of these scripts until such time that they can be converted over to keyword driven test tables (if and when that is desirable).
Thanks,
Shahadat Khan
In addition to this table-processing role, each of the Driver modules has its own set of System-Level keywords or commands also called Driver Commands. These commands instruct the module to do something other than normal table processing.
Cycle Table: SiteRegression
| |
SUITE TABLE REFERENCE
|
TABLE PURPOSE
|
StartSite
|
Launch browser and Login for test
|
VerifyTOCPage
|
Verify Table of Contents page
|
ShutdownSite
|
Logoff and Shutdown browser
|
Low-level Test Tables or Step Tables contain the detailed step-by-step instructions of our tests. Using the object names found in the Application Map, and the vocabulary defined by the Component Functions; these tables specify what document, what component, and what action to take on the component. The following three tables are examples of Step Tables comprised of instructions to be processed by the StepDriver module. The StepDriver module is the one that initially parses and routes all low-level instructions that ultimately drive our application.
Each of these Component Function modules will define the keywords or "action words" that are valid for the particular component type it handles. For example, the Textbox Component Function module would define and implement the actions or keywords that are valid on a Textbox. These keywords would describe actions like those in Table 6:
Code and Documentation Standards
| On the LoginPage, in the UserIDTextbox, Verify the Value is "MyUserID". |
Figure 3
WINDOW
|
COMPONENT
|
ACTION
|
EXPECTED
VALUE
|
LoginPage
|
UserIDTextbox
|
VerifyValue
|
"MyUserID"
|
Table 2
Table 2 reiterates the actual data table record run by the automation framework above:
The data table records contain the keywords that describe the actions we want to perform. They also provide any additional data needed as input to the application, and where appropriate, the benchmark information we use to verify the state of our components and the application in general.
A test automation framework relying on data driven scripts is definitely the easiest and quickest to implement if you have and keep the technical staff to maintain it. But it is the hardest of the data driven approaches to maintain and perpetuate and very often leads to long-term failure
Another common feature of data driven scripts is that virtually all of the test design effort for the application is developed in the scripting language of the automation tool. Either that, or it is duplicated in both manual and automated script versions. This means that everyone involved with automated test development or automated test execution for the application must likely become proficient in the environment and programming language of the automation tool.
for Technical interviews:
http://no1tutorial.com/
learn step by step technologies:
http://no1tutorial.com/